In my years securing cloud-native environments, I’ve noticed a recurring blind spot. We obsess over the “front doors” such as exposed dashboards, misconfigured RBAC, or unpatched container vulnerabilities. We harden the perimeter, but we often ignore the machinery humming inside.
Sophisticated adversaries have moved beyond simple smash-and-grab tactics. They don’t just want to run a crypto miner for a few hours; they want persistence. They want a foothold that survives a node reboot, a pod restart, or even a cluster upgrade.
The most dangerous, overlooked mechanism for this persistence is the Kubernetes Controller Pattern. By compromising or registering a rogue controller, an attacker turns the cluster’s own automation against it, creating a self-healing backdoor that is incredibly difficult to detect. It’s the ultimate “living off the land” technique for the cloud age.
Weaponizing the control loop
At its core, Kubernetes is an automation engine. It constantly compares the desired state (YAML) with the actual state (running pods) and reconciles the difference. This logic lives in Controllers.
A malicious controller works by subscribing to cluster events. Instead of deploying an application, it watches for specific triggers, such as the creation of a new namespace or the deployment of a specific secret, and automatically injects malicious code.
Scenario: The “shadow” sidecar injector
We saw this play out in the wild with Siloscape, a sophisticated malware campaign uncovered by Palo Alto Networks Unit 42. Unlike typical cryptojacking scripts, Siloscape didn’t just want compute resources; it wanted the cluster itself. It targeted Windows containers, escaped to the underlying node, and used the node’s credentials to spread via the API server.
Similarly, the TeamTNT group has been documented using the Hildegard malware to exploit the kubelet API for persistence. These aren’t theoretical classroom exercises. They are documented campaigns where attackers weaponized the control plane to turn Kubernetes against its owners.
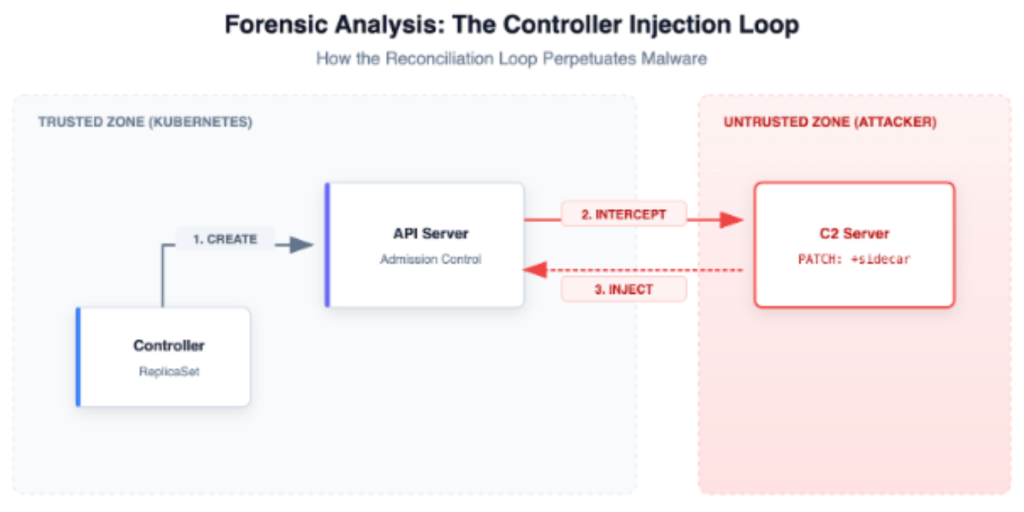
Consider an attacker who gains similar limited write access to the cluster’s API server. This access might come from a compromised CI/CD pipeline credential or a developer’s leaked kubeconfig that has just enough permission to create MutatingWebhookConfigurations but not full cluster admin rights. The attacker doesn’t need to deploy a workload directly; they just need to tell the API server to run their logic on everyone else’s workloads.
Instead of launching a conspicuous pod named mining-rig, they register a MutatingAdmissionWebhook.
Niranjan Kumar Sharma
As illustrated in Figure 1, this webhook acts as a controller. Every time a legitimate pod is created (e.g., a payment service), the API server sends the pod definition to the attacker’s webhook for approval. The webhook modifies the pod spec to inject a malicious sidecar container before it is persisted to etcd.
The hidden danger:
- It’s invisible to kubectl get pods: The malicious sidecar is often hidden deep in the pod spec, and if the attacker uses a common name like proxy-agent, it blends in with legitimate mesh traffic.
- It survives cleanup: If you delete the compromised pod, the Deployment controller creates a new one. The new one triggers the webhook again, and the backdoor is re-injected. The persistence is baked into the lifecycle of the cluster itself.
Mapping the threat: This technique maps to Persistence (TA0003) in the MITRE ATT&CK for Containers matrix. It specifically leverages the cluster’s own control loop to maintain access, making it far more resilient than traditional shell-based backdoors.
Hunting ghosts in the API
To catch this, you have to look beyond standard logs. You need to audit the cluster’s control plane configuration.
1. Audit MutatingWebhookConfigurations
Run this command to see who is intercepting your pod creations:
kubectl get mutatingwebhookconfigurationsLook for webhooks pointing to external URLs or services in namespaces you don’t recognize (e.g., kube-public or default). If you see a webhook named compliance-check pointing to an IP address outside your VPC, treat it as a massive red flag.
2. Monitor RoleBinding changes
Controllers need permissions. A rogue controller needs a ServiceAccount with elevated privileges to do damage. Monitor your audit logs for new RoleBindings that grant watch or list permissions on Secrets or Pods.
3. Check for anomalous OwnerReferences
Kubernetes objects use OwnerReferences for garbage collection. If you see pods that claim to be owned by a controller that doesn’t exist or doesn’t match standard deployment patterns, investigate immediately.
Locking down the machinery
To prevent controller-based persistence, you must restrict access to the machinery of the cluster.
- Restrict Webhook registration: Use Kubernetes RBAC to ensure that only cluster administrators (and specifically the CI/CD pipeline identity) can create or modify MutatingWebhookConfigurations. Developers should never have this permission.
- Network policies for the control plane: If you are running self-managed control planes, ensure the API server can only communicate with known, whitelisted webhook endpoints.
- Sign your images: Use an admission controller like Kyverno or OPA Gatekeeper to verify that every container image in a pod, including injected sidecars, is signed by your organization’s trusted key.
Final thoughts
Attackers are moving up the stack as Kubernetes clusters mature. They are no longer satisfied with simple container escapes; they are targeting the orchestration layer itself.
The Kubernetes Controller pattern is powerful because it offers automation and self-healing. In the hands of an attacker, those same properties create a persistent, resilient foothold. We must stop treating the API server as a trusted black box and start auditing the webhooks that glue our clusters together.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?