The future of reliability will not be defined by whether site reliability engineering (SRE) teams use AI agents, but by the conditions under which they choose to trust them. In high-stakes systems, trust is never granted because a demo looks impressive; it is earned through observability, constraints, accountability and repeated evidence that the system helps more than it harms.
Right now, many teams are exploring AI for incident response, alert triage, root cause analysis and runbook automation because modern systems generate more context than humans can process quickly under pressure. That interest is justified. But the most mature SRE organizations understand something important: the real challenge is not building an agent that can act, it is building an operating model that people can trust in production.
Trust is operational, not emotional
SRE teams do not trust tools in the abstract. They trust behavior under stress. A platform earns credibility when it helps engineers make better decisions during noisy alerts, partial outages, failed deploys and ambiguous telemetry, not when it generates polished answers in ideal conditions .
That is why generic AI often falls short in production. It may be fluent, but fluency is not reliability. Live systems demand awareness of ownership, dependency maps, escalation paths, blast radius and policy boundaries, and without that context an AI agent can sound helpful while being operationally dangerous . For SRE teams, trust starts when the agent proves it understands the system it is operating around.
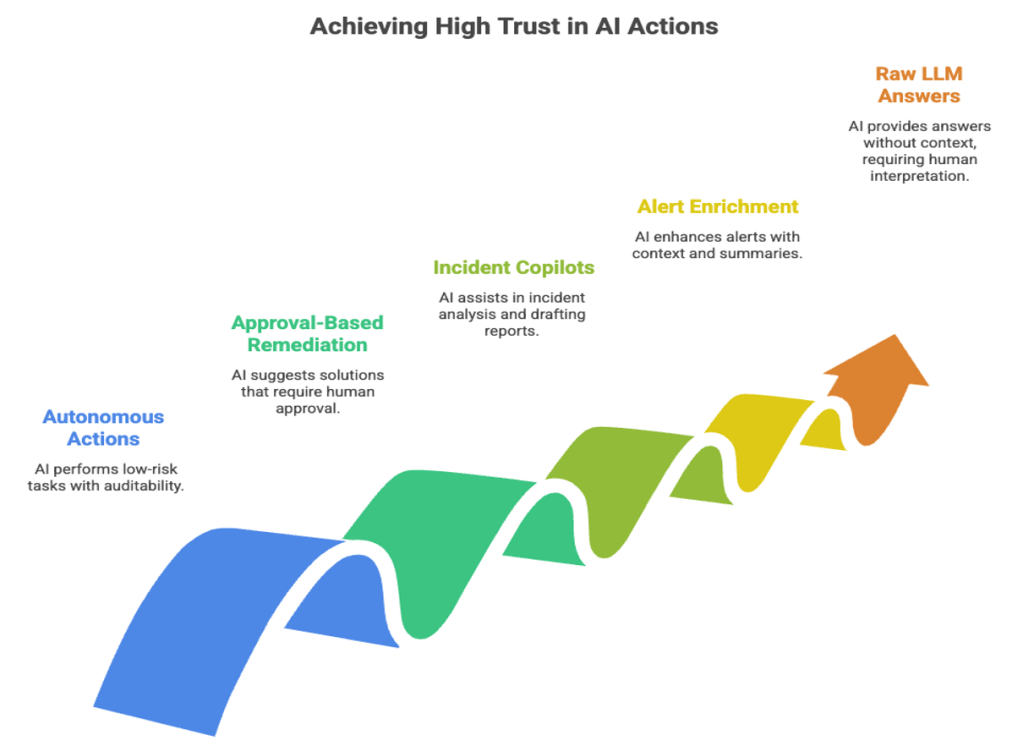
The trust ladder
Neel Shah
Teams do not move directly from experimentation to autonomy. They move up a ladder of trust, where each step is validated in production-like conditions before the next one is allowed.
The 1st requirement: Grounded observability
Before teams trust an AI agent, they need a telemetry foundation that the agent can actually reason over. If logs are incomplete, traces are missing, ownership is unclear and deployment metadata is scattered across tools, the agent will not become intelligent by magic. It will simply become confidently under-informed.
This is why observability is the real prerequisite for agentic SRE. The strongest AI SRE approaches are grounded in correlated metrics, logs, traces, changes and incident history so that recommendations are evidence-backed rather than speculative. An AI agent cannot create operational truth; it can only synthesize the truth your systems already expose.
In practice, that means teams need more than dashboards. They need clean service ownership, change tracking, incident timelines, runbooks and enough signal quality that an agent can distinguish a symptom from a cause. Without that groundwork, the AI layer becomes theatre
What grounded observability looks like

Neel Shah
Monitoring tells you that something is wrong, while observability helps explain why. AI becomes useful only when it sits on top of both layers, not instead of them.
The 2nd requirement: Clear guardrails
The fastest way to lose trust in AI is to give it authority before defining its boundaries. In operations, the question is not “Can the agent do this?” but “Under what conditions should it be allowed to do this, and who is accountable if it is wrong?”
This is where guardrails matter. Strong SRE teams want explicit permission models, approval gates, action allowlists, audit trails and rollback paths before an agent touches anything meaningful in production. That may sound restrictive, but it is exactly what makes adoption viable. Constraint is not the enemy of agentic systems; constraint is what makes them usable.
The most practical path is progressive autonomy. Let the agent start by summarizing incidents, correlating changes and suggesting next steps. Then move to read-only diagnostics. Only after consistent success should it be allowed to trigger low-risk automation, and even then, within tightly defined policies. Trust grows when the blast radius stays small.
Visual: Progressive autonomy model
| Stage | Agent role | Risk level | Human involvement |
| Stage 1 | Summarize alerts and incidents | Low | Human reviews output [cite:8] |
| Stage 2 | Pull telemetry and correlate changes | Low to medium | Human approves decisions [cite:41][cite:52] |
| Stage 3 | Recommend remediation actions | Medium | Human confirms action [cite:42][cite:43] |
| Stage 4 | Execute pre-approved low-risk actions | Medium | Human supervises and can override [cite:44][cite:52] |
| Stage 5 | Broad autonomous action | High | Rarely acceptable without strict policy controls [cite:43][cite:54] |
The 3rd requirement: Human-in-the-loop design
SRE teams are not looking for an AI replacement. They are looking for leverage. The most credible operating model is not autonomous-by-default but supervised-by-design, where agents accelerate understanding and execution while humans retain judgment over risk, trade-offs and unusual conditions .
That distinction matters because incidents are rarely just technical events. They involve business impact, customer communication, cross-team coordination and decisions shaped by context that may not exist in telemetry alone . An agent can help identify a likely bad deploy, but it cannot fully own the decision about whether to roll back during a major customer launch without broader situational awareness.
Human-in-the-loop does not mean slowing everything down. It means designing different levels of oversight for different classes of action. Low-risk tasks such as drafting an incident summary or pulling related dashboards may be automatic. Restarting a background worker might require lightweight approval. Disabling a core production dependency should remain firmly human-controlled . Mature trust comes from matching autonomy to risk.
The 4th requirement: Explainability over magic
SRE teams will not trust an agent that gives answers without showing its work. In reliability engineering, a recommendation is only as useful as the evidence behind it. Engineers need to know which metrics changed, which deployment correlated with the issue, which logs support the hypothesis and how confident the system actually is.
This is one of the biggest lessons emerging from operational AI systems. Precision matters but trust also depends on whether humans can inspect the reasoning path, challenge it and understand uncertainty in familiar terms . The best agent experiences feel less like oracles and more like disciplined collaborators: they surface context, rank hypotheses and make clear what they know versus what they infer .
That is especially important because AI failure in SRE is rarely dramatic at first. It often starts as subtle overconfidence. The agent sounds convincing, the team moves faster and only later does it become clear that the recommendation was based on incomplete evidence. Explainability is what keeps speed from turning into hidden fragility.
The 5th requirement: Evaluation in real incidents
Trust cannot be built on benchmarks alone. SRE teams need evidence from scenarios that resemble their actual world: noisy alerts, incomplete data, conflicting symptoms, repeated incidents and multi-service failures . This is why post-incident evaluation is becoming one of the most important practices in AI-assisted operations.
Some of the most interesting approaches focus on replaying past incidents and measuring how the AI would have performed once the real outcome is already known . That creates a concrete way to score whether the agent identified the right signals, prioritized the right hypotheses or recommended safe and useful next steps. It also shifts the conversation from hype to measurable reliability impact.
For SRE leaders, this is a critical mindset change. Do not ask whether the agent is impressive. Ask whether it consistently shortens investigation time, reduces false escalation, improves documentation quality and avoids introducing new operational risk . Trust follows evidence, not enthusiasm.
The 6th requirement: Fit with existing workflows
One reason some AI initiatives fail inside engineering teams is that they force a new workflow instead of strengthening the one that already works. SRE teams already have paging tools, Slack channels, dashboards, escalation policies and runbooks. An AI agent earns trust faster when it respects those patterns rather than trying to replace them all at once.
This is where incremental adoption becomes strategic. If the agent can appear in the incident channel, pull context from observability tools, draft timelines and recommend actions inside the systems engineers already trust, the barrier to adoption drops sharply. The agent becomes part of the response loop rather than another platform demanding attention during an outage.
That compatibility matters culturally as much as technically. SRE is built on disciplined operational habits. Tools that complement those habits can gain traction. Tools that disrupt them without providing value usually get ignored after the first few frustrating incidents.
If you need a more detailed guide to keep points while evaluating AI SRE tools, then check this buyer’s guide by one of the senior leaders.
What trust looks like in practice
When an SRE team truly trusts an AI agent, several things are visible. The team does not treat it as a novelty. They treat it as a bounded operational partner. They know where it adds value, where it must ask for approval and where it should stay out of the way.
Trust also changes behavior. Engineers stop wasting the first 10 minutes of an incident assembling basic context because the agent already did that well. Incident channels become more structured because summaries, timelines and likely causes are surfaced early. Runbooks improve because teams start writing them in ways both humans and machines can execute or reference . In that environment, AI is not replacing rigor. It is reinforcing it.
Most importantly, trusted AI agents reduce toil without eroding accountability. The on-call engineer is still responsible. The incident commander is still responsible. The organization still owns the reliability posture. The agent simply helps the system operate with more speed and clarity.
The leadership shift behind all of this
This is why the conversation about AI agents in SRE is ultimately a leadership question, not just a tooling question. Teams do not need another shiny automation layer. They need a clear philosophy for how autonomy, human judgment, safety and reliability will work together.
The most forward-looking SRE leaders will not ask, “How quickly can we automate incident response?” They will ask, “What conditions must be true before our engineers feel safe delegating part of this workflow to a machine?” That is a much better question because it forces investment in the real foundations: observability, governance, evidence, workflow design and measurable trust.
AI agents may become standard in reliability engineering over the next few years, but standard does not mean automatic. The teams that benefit most will be the ones that treat trust as infrastructure. They will build it deliberately, test it relentlessly and expand autonomy only where the evidence justifies it.
Closing thought
Before SRE teams trust AI agents, they need more than a capable model. They need grounded telemetry, explicit guardrails, human-centered workflow design, explainable reasoning, rigorous evaluation and operational fit with the systems they already rely on. Only then does the promise of agentic SRE become credible.
That is the real frontier. Not autonomous operations for their own sake, but reliable collaboration between humans and intelligent systems. In the end, SRE teams will trust AI agents for the same reason they trust any production system: because it behaves predictably, shows its work, respects constraints and makes the organization more resilient when it matters most .
This article is published as part of the Foundry Expert Contributor Network.
Want to join?